A few months ago, I did a podcast interview with Cliff and Buddha of Raw Urban Mobile. You can listen to the podcast here.

When I posted the interview, one of my friends who’s lost her hearing told me she needed captions.
I thought I might speed up transcribing the post if I used some kind of speech-to-text API. That’s how I ended up signing up for a free account on Google Cloud Computing. I signed up for $300 credit in a 12-month free trial.
First of all, if your audio file is less than 1 minute in length, you can directly upload it and test the API quite easily from your browser.
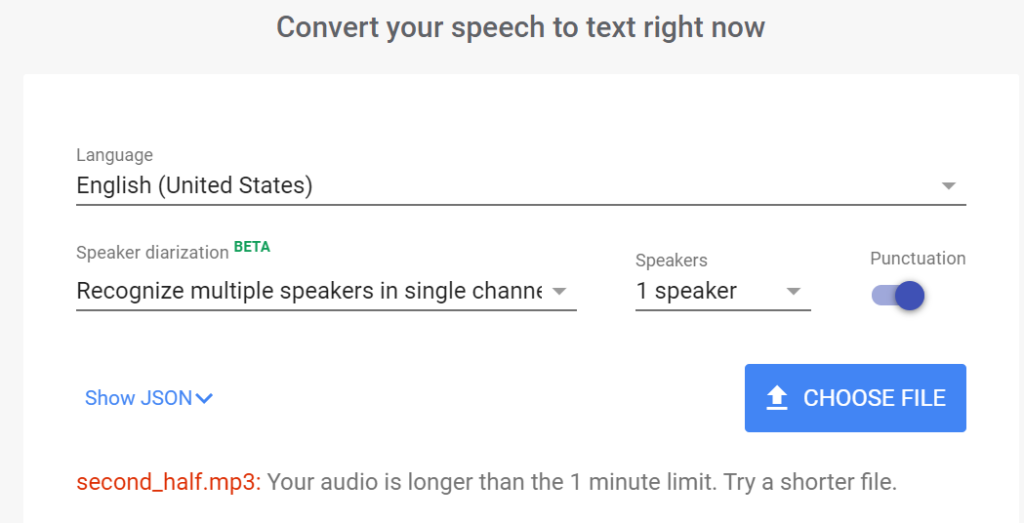
However, in my case, the audio file is over one hour long!
In such a case, you need to upload your video to Google Cloud, then write a script to do the speech to text conversion.
I think I followed this tutorial, but that was about 5 months ago so I am not exactly sure.
Splitting the Audio File
I am still using the GCP (Google Cloud Computing) free tier of the services, which limits the audio file to 30 minutes long (the limit is 480 minutes for the paid services). So I had to split my hour long audio file into two.
Here is the resulting script (will post a link to github later). Never mind that I am still using Python 2.7, I have several versions of Python installed and this still works. I was basically in a hurry to try out the translator.
import pydub
#This is a Windows library that you have to download then paste the path to #the bin here
pydub.AudioSegment.ffmpeg = "C:\\ffmpeg\ffmpeg-20190918-c2ab998-win64-static\bin\ffmpeg.exe"
#path to audio file
audio_file = "C:/Python27/Audio/kenyansupermom.mp3"
sound = pydub.AudioSegment.from_mp3(audio_file)
halfway_point = len(sound)/ 2
first_half = sound[:halfway_point]
second_half = sound[halfway_point:]
# create a new file "first_half.mp3":
first_half.export("C:/Python27/Audio/first_half.mp3", format="mp3")
second_half.export("C:/Python27/Audio/second_half.mp3", format="mp3")
Script for using the Speech-to-Text API
The script uploads the files to GCP on your behalf to a specific storage bucket that you create beforehand. You have to supply the script with your authentication credentials. The output after processing is stored in a location that you specify on your computer. After processing, the files are deleted from your storage bucket to avoid incurring costs.
# Import libraries
from pydub import AudioSegment
import io
import os
from google.cloud import speech
from google.cloud.speech import enums
from google.cloud.speech import types
import wave
from google.cloud import storage
filepath = "C:/Python27/audio2/2/" #Input audio file path
output_filepath = "C:/Python27/Transcripts/" #Final transcript path
bucketname = "example-1-yyyy" #Name of the bucket created in the step before
credential_path = "C:\Users\Downloads\h.json"
os.environ['GOOGLE_APPLICATION_CREDENTIALS'] = credential_path
def _trivial__enter__(self):
return self
def _self_close__exit__(self, exc_type, exc_value, traceback):
self.close()
wave.Wave_read.__exit__ = wave.Wave_write.__exit__ = _self_close__exit__
wave.Wave_read.__enter__ = wave.Wave_write.__enter__ = _trivial__enter__
def mp3_to_wav(audio_file_name):
if audio_file_name.split('.')[1] == 'mp3':
#print (audio_file_name)
sound = AudioSegment.from_mp3(audio_file_name)
#print (audio_file_name)
audio_file_name = audio_file_name.split('.')[0] + '.wav'
sound.export(audio_file_name, format="wav")
def stereo_to_mono(audio_file_name):
sound = AudioSegment.from_wav(audio_file_name)
sound = sound.set_channels(1)
sound.export(audio_file_name, format="wav")
def frame_rate_channel(audio_file_name):
with wave.open(audio_file_name, "rb") as wave_file:
frame_rate = wave_file.getframerate()
channels = wave_file.getnchannels()
return frame_rate,channels
def upload_blob(bucket_name, source_file_name, destination_blob_name):
"""Uploads a file to the bucket."""
storage_client = storage.Client()
bucket = storage_client.get_bucket(bucket_name)
blob = bucket.blob(destination_blob_name)
blob.upload_from_filename(source_file_name)
def delete_blob(bucket_name, blob_name):
"""Deletes a blob from the bucket."""
storage_client = storage.Client()
bucket = storage_client.get_bucket(bucket_name)
blob = bucket.blob(blob_name)
blob.delete()
def google_transcribe(audio_file_name):
file_name = filepath + audio_file_name
#print (file_name)
#mp3_to_wav(file_name)
# The name of the audio file to transcribe
frame_rate, channels = frame_rate_channel(file_name)
if channels > 1:
stereo_to_mono(file_name)
bucket_name = bucketname
source_file_name = filepath + audio_file_name
destination_blob_name = audio_file_name
upload_blob(bucket_name, source_file_name, destination_blob_name)
gcs_uri = 'gs://' + bucketname + '/' + audio_file_name
transcript = ''
client = speech.SpeechClient()
audio = types.RecognitionAudio(uri=gcs_uri)
config = types.RecognitionConfig(
encoding=enums.RecognitionConfig.AudioEncoding.LINEAR16,
sample_rate_hertz=frame_rate,
language_code='en-US')
# Detects speech in the audio file
operation = client.long_running_recognize(config, audio)
response = operation.result(timeout=10000)
for result in response.results:
transcript += result.alternatives[0].transcript
delete_blob(bucket_name, destination_blob_name)
return transcript
def write_transcripts(transcript_filename,transcript):
f= open(output_filepath + transcript_filename,"w+")
f.write(transcript)
f.close()
if __name__ == "__main__":
for audio_file_name in os.listdir(filepath):
print (audio_file_name)
transcript = google_transcribe(audio_file_name)
transcript_filename = audio_file_name.split('.')[0] + '.txt'
write_transcripts(transcript_filename,transcript)
The Result:
all right we’re back another episode of The Raw Urban mobile podcast from Shibuya Tokyo the streets inside the mobile man cave on Cliff chocolate food in the house yes we are in the streets as you can hear the cars whizzing by me hear some chatter of everyday you know people just doing everyday things and yeah here in the mobile man cave and we just chilling like family you know I’m saying so another episode not a second home Shibuya I’m loving it feel in the vibe yes and for those of you who are new to the podcast we are podcast of focus on the International Community in Japan people from all walks of life coming from everywhereto Japan and working and doing cool stuff and you know I limited dream put pursuing all types of careers and engaging in all types of activities and hobbies here in the land of Japan make a late show Speakeasy tyo Life Park Hill ruminations ……..
As you can see, it is quite a messy file with no punctuation or speaker diarization (detecting speakers and labeling who is speaking accordingly). It will take a lot of work to edit the script into something legible. At the time, speaker diarization was still on Beta but I think it is now available to use freely. (If you do test it out, let me know the result).
Testing out Paid Speech-to-Text Services by Trint
There are definitely easier ways to transcribe your files than having to write your own script, but of course you have to pay for such services.
I tried out one service (free for the first 30 minutes) with the following sample result of the second half of the file:

As you can see, the interface also lets you easily edit the file, adding comments, identify the speakers, etc. This is a better interface than GCP but I think GCP is aimed at developers while companies like Trint are aimed at end users.
Try them out for yourself and see the power of AI!
I don’t understand any of that!! I wouldn’t be able to download let alone use it!! Sorry about that though I think it will come eventually as a badly needed facility.